熟悉AWS的肯定不会对Cloudformation感到陌生,AWS官方对Cloudformation的定义如下:AWS CloudFormation 云资源服务可使开发人员和系统管理员轻松有序地创建、管理和更新相关 AWS 云资源模板。使用 AWS 模板或创建您自己的云资源。
为了最快地对Cloudformation在心中稍微有一个概念,我为大家提炼出下面的关键词:
- 利益相关者:运维或DevOps领域
- 一种管理云资源的服务
- 由AWS提供
- 通过模板文件(或者说配置文件、代码)管理云资源
代码 vs可视化操作
联想起自己以前使用云服务的体验,初学者首先应该能想到,我是不是可以通过Cloudformation来申请主机、创建Loadbalance呢,而不是手动在AWS的控制台(Console)上“点点点”呢?
是的。如果说Cloudformation仅仅使可视化的界面操作代码化,这或许只能激起代码爱好者的兴趣,我们知道代码化的许多好处,比如效率更高、可被机器自动执行。
然而因为不是所有人都喜欢代码。对于患“代码恐惧症”的人,或者习惯在界面上配置的专业运维人员来说,界面操作显然比代码更直观、拥有更友好的操作引导。
对于追求高效的工程实践来说,代码化还是界面操作并非“萝卜青菜,各有所爱”的兴趣爱好问题,而是生产力问题。
基础设施即代码
这年头流行一个词语,叫DevOps,维基百科的定义如下:
DevOps(Development和Operations的组合词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。
而我个人的理解就是,DevOps要求能把运维纳入软件开发体系,比如运用敏捷等软件开发方法、实现自动化持续集成、测试、交付、可被代码管理等等;其次,要求开发具备运维意识,将交付基础设施作为交付软件的一部分,借助云计算给开发人员赋能从而达到端到端交付的全栈能力,从而极大地提高研发效能。
在这个意义上,Cloudformation就是这样一个工具,可以将基础设施作为代码纳入到软件开发的一部分,并运用软件工程方法管理基础架构。
“基础设施即代码”给我们带来什么
在笔者所在的团队里,能写DevOps的代码已经作为开发的标配技能。在新起一个Codebase的时候,我们往往需要考虑一下内容:
一个项目的文件结构截图
- 基础设施代码 (/infra目录)
- 持续集成流水线代码(/pipeline目录, 这年头还有个词叫“流水线即代码”)
- 业务代码(包括前后端代码、测试代码,/api, /test 目录)
在一些大型的互联网公司来说,运维和开发的职权是完全分离的,开发可能仅仅只用关注业务代码部分。
实际上在一个项目启动后的前期,首先介入的可能是运维人员搭建出一套线上的开发环境(Dev)、测试环境(QA)、生产环境(Prod)用于开发的日常调试、测试人员测试以及发布项目;如果使用持续集成的方式的话,还要搭建持续集成(CI/CD)流水线。
一键自动构建云环境
借助AWS平台及其提供的Cloudformation(或者第三方工具如terraform),使用基础设施代码,我们就可以快速地构建一套完整的云环境。同时使用同样一套基础设施代码,再配置不同的环境变量,就可以快速地复制出不同的线上环境。
以Cloudformation为例:
编写Cloudformation代码,比如编写通过以下的代码,通过AWS提供的aws cloudformation命令,就可以实现在AWS创建一台可以弹性伸缩的实例。
ECSAutoScalingGroup:
Type: ‘AWS::AutoScaling::AutoScalingGroup’
Properties:
VPCZoneIdentifier: !Ref InstanceSubnetIds
LaunchConfigurationName: !Ref ContainerInstances
MinSize: ‘1’
MaxSize: !Ref MaxSize
DesiredCapacity: !Ref DesiredCapacity
ContainerInstances:
Type: ‘AWS::AutoScaling::LaunchConfiguration’
Properties:
ImageId: !FindInMap
- AWSRegionToAMI
- !Ref ‘AWS::Region’
- AMIID
InstanceType: !Ref InstanceType
IamInstanceProfile: !Ref EC2InstanceProfile
KeyName: !Ref KeyName
同时我们可以使用AWS Cloudformation designer可视化地设计我们的基础架构及其之前的拓扑结构和关联关系,并导出代码。
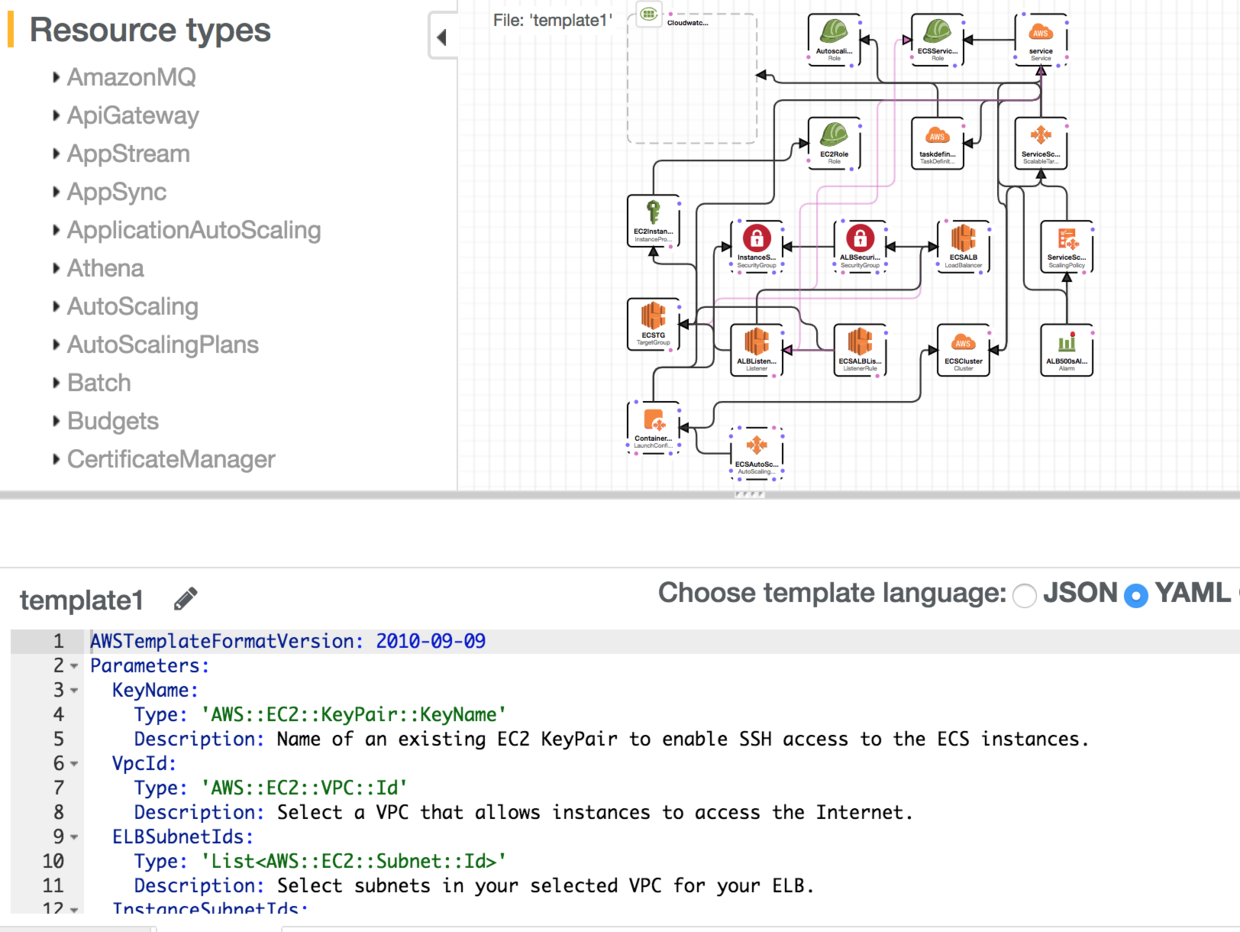
AWS Cloudformation designer
借助git等实现代码的版本管理
代码化后的基础设施,意味着可被git等版本控制工具进行管理,这意味着对基础设施的任何改动,比如更改服务器内存、更换可用区、修改域名、安全组等等,都可以通过review代码的方式进行跟踪。
而在过去,在控制台界面上进行的误操作导致线上环境出问题很难被记录下来,同时如果因为修改服务器环境配置导致的问题,可以很快通过git回滚代码的方式进行快速回滚服务器环境。
基础设施版本间无缝切换
在Cloudformation之前,AWS已经推出了命令行工具或者SDK来管理AWS的资源,与它们“命令式”操作不同的是,Cloudformation提供一种“声明式”的特性。
“命令式”操作希望你去一步步编写程序以达到最终所期望的状态,而声明式只关心你想要的资源与资源的状态,Cloudformation会自动分析达到想要的状态需要进行怎样的操作。(理解声明式和命令式的不同,可参考《声明式编程和命令式编程的比较》)
Cloudformation的声明式操作为其提供了幂等性的特性,以为我们在任何时刻、任何版本的基础架构运行新的Cloudformation代码,AWS每次都会帮助你生成相同的基础架构。
大部分人在数据库事务中了解到“原子性”。Cloudformation同样支持一种原子操作,要么成功,要么失败。失败的话可以自动回滚,而在一次失败操作中产生的资源会在回滚时被自动删除掉。
纳入持续集成/部署流水线(CI/CD)
“基础设施即代码”的代码化、自动化,为CI/CD流水线管理基础设施提供了可能。
一种理想的方式是,和修改业务代码一样,当我们要对基础设施进行变更时,通过修改基础设施的代码,提交到git仓库,触发CI/CD流水线运行基础设施代码,然后达到更新基础设施的目的。
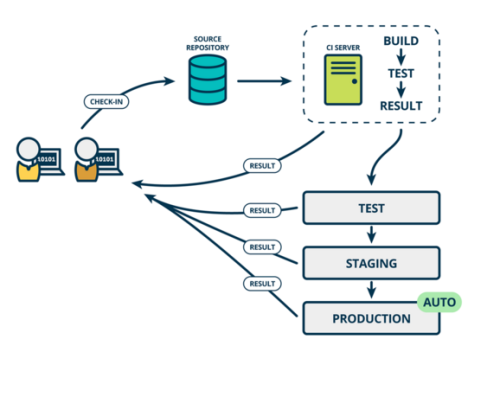 持续集成
持续集成
同时根据云计算服务商提供的反馈,更新CI/CD流水线的部署状态:红则失败绿则失败。
QA或者团队可以根据测试结果和发布计划通过流水线,将基础设施和业务代码一起推向下一阶段。
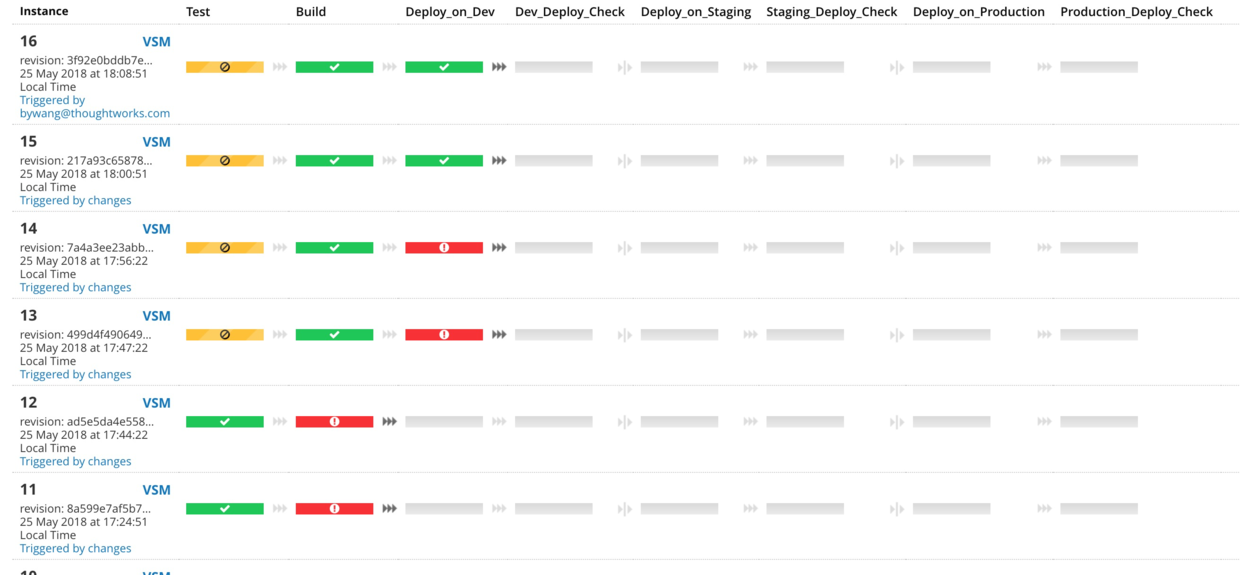
GoCD持续集成流水线
扩展思考:
2018年 ThoughtWorks 技术雷达19期为我们介绍了一款名为LocalStack的云服务的Mock框架,这意味着我们可以在本地调试基础设施代码,或者为基础架构代码做单元或集成测试。原文如下:
使用云服务时面对的一个挑战是如何在本地进行开发和测试。 LOCALSTACK 为 AWS 解决了这个问题。它提供了各种 AWS 服务的本地 测试替身 实现,包括 S3 、 Kinesis 、Dynamodb 和 Lambda 等。它基于现有的最佳工具如Kinesalite 、 Dynalite 、Moto 等构建,并增加了进程隔离与错误注入的功能。 LocalStack 的使用很简单,并附带了一个简单的 JUnit 运行器以及 JUnit 5扩展。我们在一些项目中使用过 LocalStack ,并对它印象深刻。
]]>







 山在缥缈虚无间
山在缥缈虚无间

 陈旧而意蕴十足的街头
陈旧而意蕴十足的街头








 在“南京小馆”吃了第一顿饱饭
在“南京小馆”吃了第一顿饱饭 金门大桥
金门大桥

